Ever wondered why your server crashes or your app slows down? A reliable system monitor could be the hero you didn’t know you needed. It’s not just about tracking CPU usage—it’s about staying ahead of disasters.



What Is a System Monitor and Why It Matters

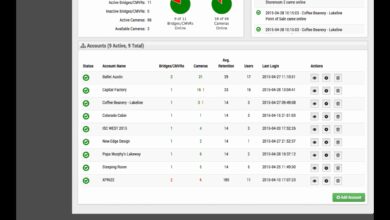
A system monitor is a software tool or hardware device designed to continuously observe and analyze the performance, availability, and health of computer systems, networks, and applications. In today’s digital-first world, where downtime can cost thousands per minute, having a robust system monitor is no longer optional—it’s essential. These tools provide real-time insights into critical metrics like CPU load, memory usage, disk I/O, network activity, and application responsiveness.
Core Functions of a System Monitor
The primary role of a system monitor is to ensure that IT infrastructure runs smoothly and efficiently. It does this by collecting data from various system components and presenting it in a way that’s easy to understand and act upon. This includes tracking resource utilization, detecting anomalies, and generating alerts when thresholds are breached.
- Real-time performance tracking
- Automated alerting and notifications
- Historical data logging for trend analysis
These functions allow IT teams to proactively address issues before they escalate into full-blown outages. For example, if a server’s memory usage spikes unexpectedly, a system monitor can send an alert, enabling administrators to investigate and resolve the issue before users are affected.
Types of System Monitoring
System monitoring isn’t a one-size-fits-all solution. Depending on the environment and requirements, different types of monitoring are employed. These include infrastructure monitoring, application performance monitoring (APM), network monitoring, and log monitoring.
- Infrastructure Monitoring: Focuses on hardware and OS-level metrics like CPU, RAM, disk space, and uptime.
- Application Monitoring: Tracks the performance and behavior of software applications, including response times and error rates.
- Network Monitoring: Observes bandwidth usage, latency, packet loss, and device availability across the network.
Each type plays a crucial role in maintaining system health. For instance, Wikipedia defines system monitoring as a critical component in system administration, emphasizing its role in maintaining service levels and ensuring business continuity.
“Effective system monitoring is the first line of defense against unexpected outages and performance degradation.” — IT Infrastructure Expert
Top 7 System Monitor Tools in 2024
Choosing the right system monitor can make or break your IT operations. With dozens of tools available, it’s important to evaluate them based on features, scalability, ease of use, and integration capabilities. Below are seven of the most powerful and widely used system monitor solutions in 2024.
1. Nagios XI
Nagios XI is one of the most established names in the system monitoring space. Known for its flexibility and extensive plugin ecosystem, it supports monitoring of servers, applications, services, and network protocols. It provides a web-based dashboard that visualizes system health and performance metrics in real time.
- Supports thousands of plugins for custom monitoring
- Advanced alerting via email, SMS, and third-party tools
- Scalable for large enterprise environments
Nagios is particularly popular among system administrators who need deep customization. Its open-source roots (Nagios Core) make it a favorite for those who prefer transparency and control. Learn more at nagios.com.
2. Zabbix
Zabbix is a powerful open-source system monitor that offers real-time monitoring of networks, servers, virtual machines, and cloud services. It’s known for its scalability and ability to handle large environments with tens of thousands of devices.
- Auto-discovery of network devices
- Comprehensive graphing and reporting
- Built-in support for SNMP, IPMI, JMX, and custom scripts
One of Zabbix’s standout features is its distributed monitoring architecture, which allows for centralized management of geographically dispersed systems. It’s ideal for organizations with hybrid or multi-cloud setups. Visit zabbix.com for documentation and downloads.
3. PRTG Network Monitor
Developed by Paessler, PRTG is a Windows-based system monitor that excels in network monitoring. It uses a sensor-based model, where each sensor monitors a specific aspect of the system—like bandwidth, ping response, or CPU load.
- Intuitive web interface with drag-and-drop dashboards
- Over 200 sensor types available
- Supports both agent-based and agentless monitoring
PRTG is user-friendly and perfect for small to mid-sized businesses. Its free version allows up to 100 sensors, making it a great starting point for teams testing monitoring solutions. More info at paessler.com/prtg.
4. Datadog
Datadog is a cloud-based system monitor designed for modern DevOps teams. It integrates seamlessly with AWS, Azure, Google Cloud, Kubernetes, and Docker, making it ideal for dynamic, containerized environments.
- Real-time dashboards with AI-powered anomaly detection
- Log management and APM integration
- Collaboration features like shared dashboards and comment threads
Datadog stands out for its ease of integration and powerful analytics. It’s used by companies like Airbnb and Shopify to monitor complex, distributed systems. Explore Datadog at datadoghq.com.
5. SolarWinds Server & Application Monitor (SAM)
SolarWinds SAM is a comprehensive system monitor that focuses on both infrastructure and application performance. It’s known for its deep visibility into application dependencies and database performance.
- Pre-built templates for common applications (e.g., SQL Server, Exchange)
- Root cause analysis with dependency mapping
- Customizable alerts and reports
SAM is particularly useful for enterprises running mission-critical applications. Its ability to correlate system metrics with application performance helps reduce mean time to resolution (MTTR). Learn more at solarwinds.com/server-application-monitor.
6. Prometheus
Prometheus is an open-source systems monitoring and alerting toolkit originally built at SoundCloud. It’s now a graduated project of the Cloud Native Computing Foundation (CNCF) and is widely adopted in Kubernetes environments.
- Pull-based monitoring model with time-series database
- Powerful query language (PromQL)
- Highly scalable and container-friendly
Prometheus excels in dynamic cloud environments where services are ephemeral. It’s often paired with Grafana for visualization. Get started at prometheus.io.
7. New Relic
New Relic offers a full-stack observability platform that includes system monitoring, APM, infrastructure monitoring, and frontend monitoring. It provides deep insights into user experience and backend performance.
- Real-time performance dashboards
- Distributed tracing for microservices
- AI-driven alerting and incident management
New Relic is ideal for organizations practicing DevOps and continuous delivery. Its ability to monitor both code and infrastructure makes it a favorite among developers and operations teams. Visit newrelic.com for a free trial.
Key Metrics Tracked by a System Monitor
A good system monitor doesn’t just collect data—it collects the right data. Understanding which metrics to track is crucial for maintaining system health and performance. These metrics fall into several categories, each providing insight into a different aspect of system behavior.
CPU and Memory Usage
CPU and memory are the most fundamental resources in any computing environment. A system monitor tracks CPU utilization percentage, load averages, and memory consumption (RAM and swap). High CPU usage over extended periods can indicate inefficient code or resource contention, while low available memory may lead to swapping and performance degradation.
- Monitor CPU idle time to detect underutilization
- Track memory leaks in applications over time
- Set alerts for sustained high usage (e.g., >80% for 5 minutes)
For example, if a web server’s CPU usage consistently exceeds 90%, it may be time to scale horizontally or optimize the application.
Disk I/O and Storage
Disk performance is often a bottleneck in system performance. A system monitor tracks read/write operations per second (IOPS), disk queue length, and available disk space. Slow disk I/O can severely impact database performance and application responsiveness.
- Monitor disk latency (response time for read/write)
- Track disk space trends to predict capacity issues
- Alert on high disk queue length indicating I/O congestion
Many organizations use tools like Zabbix or Nagios to set up alerts when disk usage exceeds 85%, preventing outages due to full drives.
Network Performance
Network monitoring is critical for ensuring connectivity and performance across distributed systems. Key metrics include bandwidth utilization, packet loss, latency, and jitter. A system monitor can detect network bottlenecks, failed links, or DDoS attacks by analyzing traffic patterns.
- Monitor bandwidth usage per interface or application
- Track round-trip time (RTT) for critical services
- Detect unusual traffic spikes that may indicate security threats
Tools like PRTG and SolarWinds offer deep packet inspection and flow analysis (NetFlow, sFlow) to provide granular network insights.
“You can’t manage what you can’t measure.” — W. Edwards Deming
How to Choose the Right System Monitor
Selecting the best system monitor for your environment requires careful evaluation of several factors. The wrong tool can lead to information overload, high costs, or inadequate coverage. Here’s a structured approach to making the right choice.
Assess Your Environment and Needs
Start by mapping your IT infrastructure. Are you running on-premises servers, cloud instances, containers, or a hybrid model? Do you need to monitor applications, databases, or network devices? Understanding your environment helps narrow down the list of suitable tools.
- Small business with 10 servers? PRTG or Zabbix may suffice.
- Large enterprise with cloud and on-prem? Consider Datadog or SolarWinds.
- DevOps team using Kubernetes? Prometheus is a natural fit.
Also consider future growth. A tool that works today may not scale with your organization.
Evaluate Features and Integration
Not all system monitors offer the same features. Compare capabilities like alerting methods, dashboard customization, API access, and integration with other tools (e.g., Slack, Jira, PagerDuty).
- Does it support SNMP, WMI, or agentless monitoring?
- Can it integrate with your CI/CD pipeline?
- Does it offer log aggregation and correlation?
For example, Datadog integrates with over 500 technologies, making it highly versatile for complex ecosystems.
Consider Cost and Licensing
Cost is a major factor. Some tools like Zabbix and Prometheus are open-source and free, while others like SolarWinds and New Relic use subscription-based pricing. Evaluate total cost of ownership (TCO), including hardware, training, and support.
- Free tools may require more in-house expertise
- Commercial tools often include support and updates
- Some vendors charge per monitored node or metric
Always request a trial or demo before committing.
Setting Up Your First System Monitor
Getting started with a system monitor doesn’t have to be overwhelming. With a clear plan, you can deploy a monitoring solution in hours. Here’s a step-by-step guide to setting up your first system monitor.
Step 1: Define Monitoring Goals
What do you want to achieve? Common goals include reducing downtime, improving performance, ensuring compliance, or supporting DevOps practices. Clear objectives help prioritize which systems and metrics to monitor first.
- Identify critical systems (e.g., database servers, web apps)
- Determine acceptable performance thresholds
- Define alert recipients and escalation paths
For example, an e-commerce site might prioritize monitoring the checkout process and database response times.
Step 2: Install and Configure the Tool
Most system monitors offer installation wizards or package managers. For agent-based tools, install the agent on each target system. For agentless tools, configure SNMP or WMI access.
- Follow vendor documentation for setup
- Secure communication (e.g., TLS, firewalls)
- Test connectivity and data collection
For instance, installing Zabbix involves setting up the server, database, and web interface, then adding hosts and assigning templates.
Step 3: Create Dashboards and Alerts
Dashboards provide a visual overview of system health. Start with high-level views, then drill down into specific components. Alerts should be meaningful—avoid alert fatigue by setting thresholds wisely.
- Create a dashboard for CPU, memory, and disk usage
- Set up email/SMS alerts for critical failures
- Use tags and groups to organize systems
Tools like Grafana (used with Prometheus) allow highly customizable dashboards with real-time graphs and heatmaps.
“A well-configured system monitor is like a security camera for your IT infrastructure—always watching, always ready.”
Advanced System Monitoring Strategies
Once you’ve mastered the basics, it’s time to level up. Advanced monitoring strategies can help you predict issues, automate responses, and gain deeper insights into system behavior.
Proactive Monitoring with Predictive Analytics
Modern system monitors use machine learning to analyze historical data and predict future issues. For example, if disk usage grows at 5% per month, the system can forecast when it will run out of space and alert you weeks in advance.
- Use trend analysis to plan capacity upgrades
- Identify seasonal usage patterns
- Reduce false positives with adaptive thresholds
Datadog and New Relic offer AI-powered anomaly detection that learns normal behavior and flags deviations automatically.
Automated Remediation and Runbooks
Why wait for a human to fix a known issue? Advanced system monitors can trigger automated actions based on alerts. This is called self-healing or automated remediation.
- Restart a crashed service automatically
- Scale up cloud instances during traffic spikes
- Execute runbooks (step-by-step procedures) via integrations
For example, if a web server’s CPU exceeds 95%, the system can automatically spin up a new instance in AWS and update the load balancer.
Log Aggregation and Correlation
Logs are a goldmine of information. A system monitor that integrates with log management tools (like ELK Stack or Splunk) can correlate events across systems to identify root causes faster.
- Centralize logs from servers, apps, and network devices
- Use log patterns to detect security breaches
- Link log events to performance metrics for context
This holistic view is essential for troubleshooting complex, distributed systems.
Common Challenges and How to Overcome Them
Even the best system monitor can’t solve every problem. Teams often face challenges like alert fatigue, data overload, and integration complexity. Here’s how to tackle them head-on.
Alert Fatigue: Too Many Notifications
When every minor fluctuation triggers an alert, teams start ignoring them—this is alert fatigue. It’s one of the biggest pitfalls in system monitoring.
- Consolidate alerts using event correlation
- Set dynamic thresholds based on time of day or usage patterns
- Use alert deduplication and suppression rules
For example, instead of alerting on every CPU spike, only alert if it lasts more than 5 minutes.
Data Overload: Too Much Information
Modern tools collect terabytes of data. Without proper filtering and visualization, it’s easy to get lost in the noise.
- Focus on key performance indicators (KPIs)
- Use dashboards tailored to different roles (e.g., ops vs. management)
- Archive old data to reduce clutter
Effective monitoring is about quality, not quantity.
Integration Complexity
Integrating a system monitor with existing tools (like ticketing systems or cloud platforms) can be challenging, especially in heterogeneous environments.
- Choose tools with strong API support
- Leverage pre-built integrations
- Start small and expand gradually
For instance, using webhooks, you can send alerts from Zabbix directly to Slack or Jira.
What is a system monitor?
A system monitor is a software or hardware tool that tracks the performance, availability, and health of computer systems, networks, and applications. It collects data on metrics like CPU usage, memory, disk space, and network activity to help prevent downtime and optimize performance.
Why do I need a system monitor?
You need a system monitor to detect issues before they impact users, ensure system reliability, meet SLAs, and support proactive maintenance. It’s essential for maintaining uptime, especially in complex or mission-critical environments.
What are the best free system monitor tools?
Some of the best free system monitor tools include Zabbix, Nagios Core, Prometheus, and PRTG (with up to 100 sensors). These offer robust features without licensing costs, though they may require more setup and maintenance.
How does a system monitor improve security?
A system monitor can detect unusual activity—like sudden spikes in network traffic or unauthorized access attempts—that may indicate a security breach. By correlating logs and performance data, it helps identify and respond to threats faster.
Can a system monitor work in the cloud?
Yes, most modern system monitors support cloud environments. Tools like Datadog, New Relic, and Prometheus are designed for cloud-native architectures and can monitor AWS, Azure, Google Cloud, and containerized workloads like Kubernetes.
Choosing and implementing the right system monitor is a strategic decision that can dramatically improve your IT operations. From real-time performance tracking to predictive analytics and automated remediation, these tools provide the visibility and control needed to keep systems running smoothly. Whether you’re a small business or a large enterprise, investing in a robust system monitor is one of the smartest moves you can make for your digital infrastructure. The key is to start with clear goals, choose a tool that fits your environment, and continuously refine your monitoring strategy as your needs evolve.
Recommended for you 👇
Further Reading: